| Search | Help |
|
|
||||
|
||||
| Introduction
|
|
|
The use of classification schemes, keywords and thesauri are central features of the formal resource descriptions provided by your service. The appeal of information gateways is based not only on the guaranteed high quality of the selected resources, but also on the facilities for subject-based access to the collection. In particular, information gateways typically provide access for both searching and browsing. Browsing (through a directory-like structure) is usually based on subject classification schemes or, exceptionally, thesauri. There are many such classification schemes from which to choose. You will need to decide which scheme suits the purpose of your gateway and the requirements of your target user group. |
|
| Issues for gateway managers
|
|
|
This chapter should help you answer the following questions:
|
|
| Classification schemes
|
||||||||||||||||||||||||||||||||||||||||||||
|
What is subject classification? Libraries have long experience of classifying resources, mainly books. The purpose of classification is to make it easier for users to find and retrieve resources. Subject classification is a method of describing resources by their subject. Universal classification schemes designed for use by libraries were first developed in North America during the nineteenth century. The most famous (and most widely used) scheme is the Dewey Decimal Classification (DDC) system, which was first produced for a small college library in 1876. Classification schemes differ from other subject indexing systems, such as subject headings and thesauri, by trying to create collections of related resources in a hierarchical structure. The use of notations or codes facilitates the creation of hierarchical subject trees. For example, using UDC we can create the following hierarchy (adapted from McIlwaine, 1995, p. 17):
By building a hierarchical structure, a classification scheme enables users to look for related items which might otherwise be missed. This facilitates browsing, both within a physical library or online. One advantage of an on-line system is that you can assign more than one classification number to a resource, since they do not need to be put in numerical order on a shelf; they can be (virtually) kept in two places at once. An Internet service can easily offer several different classification 'views' of the same resources. Types of classification schemes Classification schemes can be broadly divided into:
All of these classification types are used to some extent on the Internet (Koch and Day, 1997). Universal schemes like DDC and UDC are used by many Internet services and are readily available in machine-readable form. Subject services, however, are more likely to use a subject-specific scheme. Advantages of using a classification scheme for organising Web resources The use of classification schemes offers one way of providing improved access to Web resources. It is not enough to build a collection of resources on the Web of a specific standard or relevant to a particular audience. It is also necessary to organise and present those resources in such a way that the user can retrieve all the relevant resources quickly and easily. There are many Web guides which present resources in some kind of listing, either alphabetical or divided into ad hoc, constructed subject categories. These lists can soon become long and cluttered. Classification schemes have therefore begun to replace less sophisticated ways of listing resources. A site which uses a classification scheme to organise knowledge demonstrates several distinct advantages over sites which do not (Koch and Day, 1997): 1. Ease of browsing Classified subject lists can easily be browsed in an online environment. Browsing is particularly helpful for inexperienced users or for users not familiar with a subject and its structure and terminology. In addition, the structure of the classification scheme can be displayed in different ways as a navigation aid. The classification notation does not even need to be displayed on the screen, so an inexperienced user can have the advantage of using a hierarchical scheme without the distraction of the notation itself. 2. Narrowing searches and viewing related resources When queries are limited to individual parts of a collection (filtering), the number of false hits is reduced, i.e. precision is improved. Classification schemes are hierarchical and therefore can also be used to get an overview of resources covering broader or narrower topics as you move up or down the hierarchy. This offers users the opportunity to view related resources which may be relevant to their information needs. 3. Providing context The use of a classification scheme gives context to the search terms used. For example, the problem of homonyms (words which have the same spelling but a different meaning) can be partly overcome, because the context of the broader subject area or discipline will in most cases unambiguously indicate their meaning. 4. Partitioning and manipulating databases Large classified lists can be divided logically into smaller parts if required. Using an established or standard classification scheme has further advantages: 5. Potential to permit multilingual access to a collection Since classification schemes often use language-independent notations (numerical or alphanumeric), these notations can be linked to as many of the available translations of the classification terms as you need. This offers the possibility of searching for terms belonging to a particular notation in various languages, and it also allows for the creation of browsing sections in more than one language. Other languages can be added later with very little effort, and without the need to classify the resources again. DDC and UDC have a good multilingual capability as the codes they produce are entirely numerical and their schedules have been widely translated (into nearly as many as 30 different languages). A version of a scheme in an appropriate language will not always be available. 6. Improved interoperability The use of an agreed classification scheme could enable improved browsing and subject searching across databases. 7. Greater stability An established classification does not usually become obsolete. The larger schemes are undergoing continuous revision, although they are normally also formally published in numbered editions. Some classifications may have to be changed when a new edit ion of a scheme is published, but it is unlikely that every single resource will have to be reclassified. 8. Greater familiarity Some classification schemes are well known by a large user group. Regular users of libraries will be familiar with at least part of one or more of the traditional library schemes. Members of a subject community are likely to be familiar with their (subject-specific) schemes as well. Indeed some classification schemes are available in machine-readable form. Internet services which use established classification schemes may therefore have an advantage over those which use a home-grown scheme or none.
Disadvantages of using a classification scheme for organising Web resources However, classification schemes also have some disadvantages: 1. Splitting up logical collections of material Classification schemes often split up collections of related material, although this can be partly overcome with good cross-references and by assigning multiple class numbers to one resource. 2. The illogical subdivision of classes Some popular schemes do not always subdivide classes in a logical manner. This can make them difficult to use for browsing purposes. 3. Delays in assimilating new areas of interest Classification schemes, since they are usually updated through formal processes by organised bodies, often have difficulty in reacting promptly to new areas of study and changing terminology. The most appropriate classification scheme for your service There are many factors to consider before choosing the most appropriate classification scheme for your service. Comparing the different types of scheme is one useful approach. 1. Creating your own scheme versus using an existing scheme When a new gateway is being developed, you may be tempted to invent a new classification scheme for it. Inventing a new scheme has some advantages, but may also create new problems. Advantages of creating a new classification scheme:
Creating a new classification scheme also has disadvantages:
Choosing an existing classification scheme avoids having to deal with some of the above issues. The scheme has already been made and it does not require any additional time or money to develop it.
2. Established library classification schemes versus schemes developed for Internet usage The established library classification schemes have developed over a long period of time, sometimes as long as 100 years. This means that their conception of the world can be outdated and this may be reflected in the structure. For example, all universal schemes have had to take account of the rapid growth in electronics and computing in the second half of the twentieth century. Updating classification schemes takes a long time and sometimes the updated versions lack consistency, with new concepts being placed under illogical headings. Due to their size, the classification schemes do not update very often and, when they do, they tend to update one subject at a time. Traditional schemes can therefore be rather complex to use. The good thing, however, about general library classification schemes is that they are universal schemes. They are built to classify an entire world with all its content. The schemes developed for Internet usage are of course relatively young, often developed over the last few years. This means that they are often still incomplete and continuously updating, trying to cover new subject areas as they go along. These schemes mirror the modern and changeable world. Sometimes they concentrate on a few areas of interest, ignoring the rest, sometimes they try to cover the whole world in the same way as the universal library classification schemes. However, many home-grown schemes display severe weaknesses which hamper correct and efficient usage: failures in logic and hierarchy; incorrect subdivision of classes and application of multiple hierarchies; errors in terminology and in internal links and relationships between classes, and so on. There is also no requirement for subject services to use all layers of the classification hierarchy in an established system. Some current schemes organise material based on the first three levels only of a decimal scheme like DDC.
3. Universal classification schemes versus subject-specific schemes Universal classification schemes and subject-specific schemes are designed with different purposes in mind. A new gateway would need to choose a scheme relevant to the target audience for whom the service is being created. Where a gateway gives access to resources from all areas of knowledge, published throughout the world and in many languages, and intended to be offered to an international multi-disciplinary community of users, an existing universal scheme should be selected. If the service is a subject-specific one aimed at researchers within, say, the engineering community, it would be better to use a subject-specific classification scheme, if a suitable scheme is available. An alternative might be to use the appropri ate part of a universal scheme. Problems will occur for services covering subjects for which several different schemes exist (e.g. the earth sciences) or services which cover more than one subject area (e.g. the social sciences). In these cases, mapping and linking between schemes, the use of concordances for conversion, or extensions of a scheme may help.
4. National (monolingual) schemes versus international multilingual schemes The choice between a national monolingual scheme and international multilingual schemes also depends on your subject and target group as well as on the purpose of the service. If a gateway only aims at a single user group within a country or at a specific language community and does not see any other potential users for the service, it could probably successfully use a national or language-based classification scheme. You would also possibly gain from the familiarity of a nationally-based scheme if you use one which is common in libraries. If, on the other hand, a gateway aims at a user group which is international (or which is intended to become international in the future), it would be better to use an international multilingual scheme, if one is available. If a gateway is thinking of cross-browsing or cross-searching with other gateways, it needs to consider the possibility of mapping to other schemes at this stage. Note that some national schemes are available in a multilingual version, for example, the Nederlandse Basisclassificatie, which is the national scheme designed for use within the Dutch national cataloguing system. This scheme is available in English and (an adapted) German version as well. The English scheme is used on the Web in DutchESS; the German one is used by some German libraries which have adopted the Dutch Pica library cataloguing system.
Making your choice: issues to consider Your decision about the classification scheme you are going to use should also entail exploring the following important issues: 1. The scope and coverage of your service, and its primary target audience The scope of the service, its subject, language and geographic coverage, and its target user population should be the most important consideration in the choice of classification scheme. If the service includes all subjects and is aimed at a wide audience of Internet users, a universal classification scheme would be a good choice. If, however, the collection focuses on a limited subject area and there is a suitable international subject-specific scheme available, this should be used; if your service is a national service, you may want to consider a national general scheme. If no comprehensive scheme covering the geographic area or subject is available, a classification structure will have to be created especially for the service, either from scratch or (preferably) by extending an existing scheme. 2. Maintenance issues The decision concerning which scheme to adopt may also be affected by the level of familiarity that your staff have with a specific scheme, as well as by the maintenance level provided by the owner of the classification system. If the staff are not familiar with the chosen scheme, this could slow down the growth of the gateway in the initial period. 3. Quality, status and availability of the scheme Questions to be asked regarding this issue are:
4. Interoperability issues The important consideration here is whether there are any mappings available between the candidate schemes and other established subject-specific or universal schemes which can secure interoperability to other services, now or in the future. 5. Costs How do the costs of the different schemes and methods compare? This includes costs for information specialists, technicians and (if necessary) translators as well as for servers and software being used. The initialization of a service will require more investment, because all the issues discussed here need to be investigated, and the system chosen will have to be set up. When the service is up and running the costs will be lower. Amending and mapping classification schemes Implementing classification schemes may present you with a number of issues. You may wish to adapt, restrict or extend the scheme you have chosen. There are also a number of very good reasons why you may want to map between multiple schemes. This section briefly summarises these issues. Adapting a classification scheme For classification schemes to be effective as browsing aids in subject gateways, they need in some cases to be reduced in complexity and/or reordered. A detailed table of the changes made should be kept, so that the locally used variant can be adapted easily whenever the original scheme is updated. For instance, when the hierarchy is rearranged, a mapping to the equivalent placings in the original scheme should be kept. There are several ways in which classification schemes can be adapted: 1. Omitting empty classes A very unequal distribution of resources throughout a classification scheme can be confusing for the user and frustrate the browsing process. Omitting empty classes may be necessary in order to create a user-friendly browsing structure. If there are only a few empty classes or branches, the best policy is to mark the classes as empty in your browsing structure and navigation area (as done in EELS). The system will still appear as a coherent and logical whole. If there are many empty areas, the display could hide the empty classes. Our advice, however, is to classify the individual resources in as much detail as possible in the chosen system, but to display them for the time being in the broader/parent category. This allows for a fully expanded display as soon as there are enough resources for a meaningful finer substructure, without requiring any reclassification efforts. In any case, all resources should be displayed in order to keep consistency between browsing and searching the service. 2. Rearranging hierarchies It may be necessary to rearrange the hierarchy to make the browsing structure easier to use. Sometimes the hierarchy needs a more logical arrangement to help users to find their way through it. Sometimes an important 'branch' deep down in the tree structure needs to be lifted closer to the top of the hierarchy so that it can be found more easily. In the end, if there is a potential conflict between the purpose of the gateway and the purpose of the classification scheme, it is the classification scheme which needs to be rearranged. If you are planning to include cross-browsing facilities in your gateway, rearranging hierarchies should be avoided as it complicates interoperability with other systems. 3. Renaming captions Renaming captions is another way of adapting a classification scheme. A classification scheme may use complicated technical terms which would be difficult for the target audience to understand in a gateway designed for schoolchildren. In these cases, renaming adds value and user-friendliness to the service (cf. DDC for children and DDC for end-users). The renaming should be done in a similar way throughout the service in order to keep the service consistent and the language level the same. Extending a classification scheme Sometimes an existing classification scheme is not detailed enough in particular areas or omits subject categories closely related to the gateway's coverage. If these are important areas for the gateway, then the classification scheme needs to be extended. There are several different ways of extending a scheme:
Again, document your extensions carefully so that you can identify these parts of your service and exclude them when carrying out operations based on your original scheme, such as adding resources from another service or cross-browsing. Remember, any mappings also need to be changed when changing your local scheme. Consider that you have to maintain all the changes throughout the lifetime of your service. The extensions could be very useful and necessary for the service, but remember that they always involve extra costs, for instance in the form of extra work when adding resources to the service. Conversion and mapping between classification schemes Mapping between different classification systems will become an increasingly important activity for subject services, in order to perform the following tasks (among others):
Producing such a mapping is often difficult and time-consuming because of theoretical, conceptual, cultural and practical differences between the systems. Mappings have to apply many different types of equivalence; one-to-one relationships are certainly not sufficient. The mapping can be carried out between two or more systems or as a mapping to a universal system like DDC as a 'switching system' or 'interlingua'. The latter alternative is needed when trying to secure wide interoperability or when there is a small overlap between the used classifications. If there are no 'official' conversion tables available, an improvement in the task of classification could still be made by extracting, from existing databases, linkages between different classification schemes or between indexing terms and classification for the same object, and using these linkages to construct a conversion algorithm. In this field, neither theory nor practice is very mature. We recommend that you should seek advice and assistance from experts in the area.
|
||||||||||||||||||||||||||||||||||||||||||||
| Keywords and thesauri
|
|
|
Why use keywords? In addition to the use of classification within an information gateway, information retrieval can be enhanced through the insertion of terms, or keywords, in a keyword field within each record. Such a practice has been common in the library world for many years as a means of aiding users to search abstracting and indexing services and library catalogues. While classification of the records in an information gateway allows the presentation of groups of related documents in well-defined subject areas, keywords are used to give a detailed description of the concepts covered by the individual document and are mainly used as an aid to searching. The concepts covered by keywords are usually more specific than those of classes within a classification scheme, and consequently several keywords may be needed fully to describe a document. Individual keywords may therefore describe sub-topics within the page or site catalogued, whereas usually only one or two class numbers will be assigned to describe the overall subject content. As noted elsewhere, keywords are generally applied to records as an aid to searching the catalogue (although they may also occasionally be used as a method of browsing - see the section on thesauri). Depending on the type of keyword system used and the policy adopted by the gateway in applying it, the added terms should improve the accessibility of individual records. They may also aid searchers by providing a feel for the philosophy and likely coverage of the gateway. An important function is to suggest to users new or more focussed terms with which they can search. Controlled versus uncontrolled It is strongly recommended that some sort of keyword system be used when cataloguing sites for an information gateway, but it is important to decide whether or not to use a controlled vocabulary as the source of the keywords used. A policy involving the use of uncontrolled vocabularies would consist of inserting into a keyword field terms relating to the subject content of the page or site which may or may not be contained within the title of the document or included in any description that may have been applied to it. The keywords used will usually be suggested by an inspection of the site being catalogued or from the cataloguer's knowledge of the subject area. If the keyword field is included in your search, then such keywords should improve the recall. The drawback with the use of uncontrolled keywords is that there are no standard, agreed terms for particular topics. This can cause problems not only with different spellings but with the use of different synonyms or near-synonyms to represent the same topic. Thus a search for the term 'labour relations' will not pick up records indexed with the term 'industrial relations'. Recall can be further improved by the correct and comprehensive application of a controlled vocabulary of standardised keywords. As with classification systems, controlled vocabularies may be general in nature, such as the Library of Congress Subject headings (LCSH), or else be devised for one particular subject domain, such as the MESH vocabulary devised for the field of medicine. Since the majority of controlled vocabularies have been created for use with journal abstracting services, a suitable subject-specific system can usually be found by studying the major services in your subject area. Permission from the authors of the vocabulary should of course be obtained before using it within your gateway. A problem with the use of controlled vocabularies is the constantly evolving nature of human knowledge resulting in the continual development of new terminology. As with classification schemes, major vocabularies periodically appear in new editions incorporating new terms, but it may happen quite frequently that a term cannot be found to describe the required content. There may also be problems with the degree of specificity of the scheme; that is, a term which is sufficiently specific may not be found. The above problems can be alleviated by adding uncontrolled terms to records where a suitable controlled term cannot be found. A consequence of using a controlled vocabulary is the need to make users aware of the vocabulary so that they are able to search on the allowed or preferred terms. This adds an extra complication to the gateway's interface, since the user will need to be able to search a version of the vocabulary for a suitable term if they are to make fullest use of controlled vocabulary indexing. If the user is expected to search a copy of the vocabulary to select terms for a search, it is best to maintain a local copy of it which features only those terms which are present in your catalogue. This is particularly the case when the vocabulary is a large one and many terms within it would result in 'no hits'. Indexing policy The search system your service uses and the search options you make available to the end users will, of course, have a critical effect on the users' experience of the service. However, as mentioned previously, the indexing policy of the gateway and how the ketwords are added will also have a significant effect. As well as deciding whether to supplement terms from a controlled vocabulary with uncontrolled terms, an indexing policy should stipulate to what degree of specificity documents are to be indexed. The main issue here is that in cases where only keywords representing the main topics of the document are applied, the precision of a search can be increased if the search system has a mechanism for restricting searches to the keyword field. It is generally recommended that you include all relevant keywords, including those occurring in the document's title and description, in the keywords field. However, if you decide not to restrict searches to a keyword field, you should be aware of the potential problems this might cause. Search results are sometimes displayed using ranking mechanisms which look at the number of times a searched-for keyword occurs in each record found and use this to order the results. Repeating terms already used within the description, for instance, may skew this process. Thesauri - hierarchical controlled vocabularies Controlled vocabularies may consist of large numbers of terms; they are also likely to comprise terms which are related to each other in various ways, particularly in broader/narrower relationships. Most of the major controlled vocabularies consequently have their terms arranged into hierarchies very similar to those of classification schemes. The most common relationships between terms are:
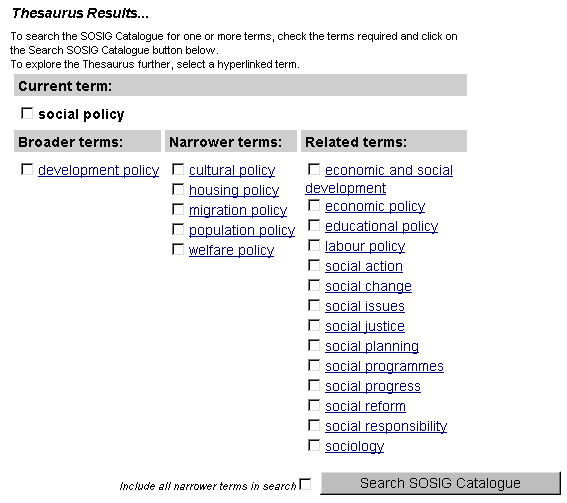
The HASSET thesaurus produced by the Data Archive at the University of Essex, as used in the Social Science Information Gateway (http://www.sosig.ac.uk/roads/cgi/thesaurus.pl) A hierarchical vocabulary or thesaurus makes it much easier both for the indexer to add relevant terms to the record and for the catalogue user to search on them. In principle, the user can begin at a top level term and browse down through the thesaurus until they come to a term closest to the topic in which they are interested . Some method for searching the thesaurus by keyword will also be available. In practice, a combination of searching the thesaurus and then browsing a small part will often give the user the best results. The hierarchical structure is also useful in providing an overview of the structure of the subject domain (in a subject-specific system) for users who are unfamiliar with it, as with the browse structure derived from a classification scheme. It may also be possible to use a thesaurus in place of a classification scheme for browsing a catalogue, but the structure may not be as suitable for browsing as that of a classification scheme built for the purpose. 
The figure above shows the medical gateway OMNI (http://www.omni.ac.uk/search/thesaurus/), which uses the MESH subject-headings to index its records. Selecting a particular term within the thesaurus produces a display of all records which contain this term. Multilinguality You may wish to create your own multilingual database which will allow users to perform searches within the catalogue, even though the original language of the record is unknown to them. Another approach would be to allow several separate databases in different languages to use the same thesaurus. As with classification schemes, it is possible that terms within a thesaurus can be represented by a unique identifier. If such a notation is used within catalogue records as well as or in place of the terms themselves, the display of keywords in records (or within the thesaurus) can be done in any number of different languages. However, any multilingual approach will require a great deal of time and effort - which is one reason why there are very few such multilingual services available. |
|
| Staff issues
|
|
|
Subject classification and indexing are activities that in the library environment have been carried out by various trained professionals: subject specialists, cataloguers, information specialists or maintainers of (specialist) bibliographic databases. The quality of any browsing structure depends on the accuracy of the classification. The correct assignment of classification codes, keywords or thesaurus terms requires knowledge of the subject area as well as of the keyword system or classification scheme that is used. The process of assigning terms can be time-consuming. Once you have decided that you want to add keywords and/or classification codes to the resource descriptions in your gateway, you will have to decide who among your staff has the necessary skills. This should be considered in relation to the question of who is going to be responsible for selection and/or cataloguing of the resources. One possibility is to let the same people select, index and catalogue the resources, which may be efficient; another option is to let people with different backgrounds and skills do the various tasks, which may make better use of the individual skills of various professionals. A few possibilities:
|
|
| Browsing and searching
|
|
|
The methods for classification and subject indexing discussed so far should be evaluated in terms of their use in enhancing search and browse facilities in your gateway. Browsing Most services offer some kind of browsing facility. This may be an established classification scheme, a home-grown scheme, or some controlled vocabulary. This structure is typically presented to the user as a hierarchy starting from a list of terms, narrowing down till the user arrives at a list of resources. A list of resources may also be presented at each stage of the hierarchy. Probably the best way to create a browsing structure is to use a classification scheme. Apart from providing a basis for the browsing structure, the numerical codes as well as the terms in whatever language they are available may be used for searching purposes as well. Numerical codes used for classification need not be displayed on the browsing pages. As noted previously, thesauri with explicit and complete hierarchical structures are also suitable for this purpose. Searching Many services offer 'advanced' search options, where searches on formal attributes (author, title) can be combined with terms specifying the subject of the resource. The latter may be uncontrolled keywords or terms taken from thesauri, subject headings, authority files and other vocabularies. Searching free-text descriptions may also provide an additional way of finding resources, either in combination with controlled keywords and/or classification codes, or in searches restricted to this field. Classification schemes, although mostly used to provide a browsing structure, may also be used to enhance searching. These search options can be integrated in various ways in the user interface of your service. Sections of the classification scheme can be offered as a filter on the search, limiting the results of the query to a certain subject category of the database. The best way to do this is probably to offer a list of all alternative sections/classifications for selection, allowing the user to choose either one or several sections. An expert alternative would be to offer the classification field for direct searching with a truncation option, if the notation is made visible. On the browsing pages a search option could be offered limiting the search to the currently viewed class and the subclasses below. EELS and Yahoo! are examples of this approach. Harvesting the documents in your service (and/or in your subject area in general) and providing a full-text index are other ways of expanding the services offered by your gateway. The user could choose to search either the record descriptions and/or the full text database. The latter would of course increase recall (even dramatically), but reduce precision. One example of cross searching a catalogue with a harvested index can be seen at http://eels.lub.lu.se/aeels/search.html
Cross-browsing and cross-searching Some subject areas are currently covered by more than one gateway; for example, engineering is covered by both EELS, EEVL and AVEL. This can be confusing for the users, who will have to have extensive knowledge about all existing gateways, to be able to decide which one(s) are most likely to answer their question. It is possible that one gateway may be more suitable for one subtype of resources than another, but users will have to compare various gateways, to get to know their strong and weak points, their exact coverage, biases and so on. The same problems arise for people interested in inter-disciplinary resource discovery. A possible way out of this dilemma from the service's point of view is to opt for more co-operation with other services in the same subject area. One way to co-operate is to enable the cross-searching and/or cross-browsing of gateways. Cross-browsing two or more gateways is potentially a useful way of combining logically separate or distributed services, but it is difficult to achieve in practice. The gateways have to use identical classification schemes and the classification codes must be the same, so that a combined service can be generated, enabling a user to browse everything within the same virtual space; if identical schemes are not used, this becomes extremely difficult, if not impossible. Furthermore, classification is often a subjective activity and this would affect how combined subject gateways could be browsed. Nevertheless, cross-browsing through visible links between the browse sections of two or more gateways, without hiding their independence, can be accomplished by mapping methods as described previously; DESIRE II is currently testing different methods. Cross-searching is relatively easy to provide in a networked environment, especially where the same search and retrieval protocols are in use. The resource description format has to be similar, though, and fielded search requires in addition semantic equivalence between the content of the fields in all services. Cross-searching has been tested by the ROADS project and can already be implemented in gateways based on the ROADS software (Kirremuir et al., 1998). Cross-searching of information gateways poses a problem for the use of controlled vocabularies. As with cross-browsing using classification schemes, cross-searching only becomes possible if either the different catalogues use the same controlled vocabu lary or if a mapping has been made between two or more different schemes. The latter possibility poses the same problems as are found when cross-mapping classification schemes and clearly it would be easiest if agreement could be reached on the best vocab ularies to use within particular subject areas. Cross-searching and cross-browsing are more extensively covered in the Interoperability chapter. The User Interface Implementation chapter will tell you more about how to present browse and search facilities in your user interface. |
|
| Future developments - automated solutions
|
|
|
Automatic classification As traditional classification is a time-consuming and expensive process, it is obvious that investigations into the use of automated solutions are worthwhile. At the same time, classification is an activity where a significant level of human expertise, abstract thinking and understanding is needed and this is not easy to replace by artificial intelligence or expert systems. There are no known examples of traditional library classification being undertaken completely by computer software. Knowledge structuring on the Internet has to cope with far larger numbers of resources, exponential growth rates and a high risk of changes occurring in documents which already exist. This is the background to a growing number of research projects and experimental systems which are trying to support knowledge-structuring activities on the Internet with automatic methods. Most of these projects use methods of derived indexing, i.e. they extract information from the documents and then use it for structuring tasks. Automated classification will probably not replace intellectual classification as far as quality subject services are concerned, but will rather support and complement selection and subject indexing efforts. Intellectual classification is always needed to validate and improve the automatic methods. However, robot-generated databases, as an add-on to quality services in a subject area, will be automatically classified. One practical goal in DESIRE II is to explore simple applications of automated classification methods on a robot-generated subject index to the Web. Many different tests will be carried out on the 'All' Engineering (AE) robot-generated database of engineering documents from the Internet. The effort required will be studied and the resulting outcomes evaluated. A pilot service of the 'All' Engineering Web index will offer a full classification and browsing structure with the most suitable solution found during the project. In addition, a comprehensive state-of-the-art report on projects, methods, alternatives and problems concerning automatic classification will also be presented. The results of DESIRE II will be included in the next edition of this handbook. Clustering Clustering is a method which, like classification, aims to bring together groups of closely related documents. However, clustering is an automatic process, which groups documents according to specific criteria expressed in an algorithm. The groups are normally not (hierarchically) related to each other and are of very different sizes. The subject covered by a cluster is very hard to describe. Every time that new documents are added to the collection the clusters have to be calculated again and the outcome can be different. Documents can frequently move to other clusters. Clustering methods (which is a form of derived, a posteriori classification) should rather be compared with methods of automatic classification using established (a priori) classification systems used to assign classification to documents. Clustering is not suitable for presenting a stable structure for browsing large gateways in which documents need to be grouped into clearly defined and related subject sections; indeed, it is not meant to be used for that purpose. |
|
| Further information
|
|
|
A more detailed analysis of the use of classification schemes in Internet resource description and discovery and a list of services using them can be found in the DESIRE I report produced by Koch and Day (Koch and Day, 1997). This report describes the use of several classification schemes on the Internet in some detail and provides an introduction to the use of automated classification techniques on the Internet. Another useful Web page which lists some Internet-based services that use classification schemes for organising resource discovery services is Gerry McKiernan's Beyond Bookmarks page (McKiernan, 1996 and ongoing). |
|
| Glossary
|
|
|
Assigned indexing Manual addition of meaningful terms to the records in a gateway to facilitate searching, usually taken from a pre-existing controlled vocabulary (see also derived indexing)
|
|
| References
|
|
|
Biz/ed, http://www.bized.ac.uk/ DESIRE, http://www.desire.org/ EELS, http://eels.lub.lu.se/ OMNI, http://www.omni.ac.uk/ SOSIG, http://www.sosig.ac.uk/ T. Koch, Controlled vocabularies, thesauri and classification systems available in the WWW. DC Subject, D. Hiom, Mapping classification schemes (Bristol: SOSIG, 1998) E. Miller, P. Miller & D.Brickley, Guidance on expressing the Dublin Core within the Resource Description Framework (RDF), 1999 J. Kirriemuir, D. Brickley, S. Welsh, J. Knight & M. Hamilton, 'Cross-Searching Subject Gateways - The Query Routing and Forward Knowledge Approach', D-Lib Magazine (January 1998). T. Koch & M. Day, The role of classification schemes in Internet resource description and discovery (DESIRE project: UKOLN, Bath, 1997). T. Koch, 'Nutzung von Klassifikationssystemen zur verbesserten Beschreibung, Organisation und Suche von Internet Ressourcen', Buch und Bibliothek 50:5 (1998), 326-335. T. Koch, A. Ardö & L. Noodén, 'The construction of a robot-generated subject index', EU Project DESIRE II D3.6a, Working Paper 1, 1999. T. Koch & D. Vizine-Goetz, 'Automatic Classification and Content Navigation Support for Web Services. DESIRE II co-operates with OCLC' in Annual Review of OCLC Research 1998 (1999). T. Koch, Controlled vocabularies, thesauri and classification systems available in the WWW (ongoing). I. C. McIlwaine, Guide to the use of UDC: an introductory guide to the use and application of the Universal Decimal Classification, rev. ed. (The Hague: International Federation for Information and Documentation (FID), 1995). G. McKiernan, Beyond bookmarks: schemes for organising the Web (Iowa State University, 1996 and ongoing). |
|
| Credits
|
|
|
Chapter authors: Phil Cross, Michael Day, Traugott Koch, Marianne Peereboom, Ann-Sofie Zettergren |
|
| << P R E V I O U S | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | N E X T >> |
| Go to the table of contents |
| Return to: Handbook Home DESIRE Home |
Search | Full Glossary | All References Last updated : 26 April 00 |
Contact Us © 1999-2000 DESIRE |
