| Search | Help |
|
|
||||
|
||||
|
Introduction
|
|
|
This chapter provides a starting point for technical specialists who are considering using harvesting, indexing and automated metadata collection within their information gateway. An information gateway which works like this consists of three separate mechanisms:
The main software components used in the DESIRE II project are reviewed. The rest of this chapter describes how to glue the different pieces together into a running environment that can accommodate further development. |
|
|
Background
|
|
|
The core function of an information gateway is to make bibliographic records available for advanced searching. The ANSI/NISO Z39.50 protocol is specially designed to support very detailed request and retreival sessions. That is why the Desire project uses the Zebra server software which implements that very protcol. Since ANSI/NISO Z39.50 isn't very widely supported (none of the major Web browsers provides a client) we need to use a gateway. The gateway's main functionality is to channel requests passed via HTTP to a Z39.50 server and return an appropriate response. It also has to keep track of all the different sessions for all users who access the gateway. Finally, we obviously should have a robot to collect the Web resources in the first place. There are many robots available, but we need one that can deal with our particular interest in metadata as well as our need to adjust robot output in a way that makes it easily available to the Zebra server. Combine fulfils both these requirements. |
|
|
Harvesting and Combine
|
||||
|
The harvesting metaphor was coined because of the strong similarities between the automated collection of Web resources and real-world harvesting. Both of these tasks raise three key issues:
The first question is concerned with how best to discover Internet resources and is primarily a matter of manual selection. Those aspects are described in a separate chapter. It does, however, highlight an important problem that begs for computerised support. A harvester works very well on a field of corn but it performs poorly in other contexts, for instance when we're looking for rare mushrooms in a forest. We simply cannot take everything and then sift the mushrooms from the wood, grass and pebbles. A similar line of reasoning applies to a Web robot. It would be a huge waste of time and resources to make a robot crawl around the entire .com domain in order to harvest any page concerning the sale of fountain pens. While it is possible to employ subject specialists to detect valuable Web resources and librarians to catalogue them, such an approach is relatively expensive. For this reason it is tempting to design a Web robot that, when given a promising starting point, is able to select which trails to follow.
The last two questions are easier to approach from the point of view of an information analyst who wishes to design a Web robot so we'll dispense with the agronomics. Instead we shall turn our attention to how the Combine system is designed to serve as an integral part of an information gateway. Combine is an open, metadata-aware system for distributed, collaborative Web indexing and it is freely available. It consists of a scheduler, a couple of robots, and receivers that process and store robot output. 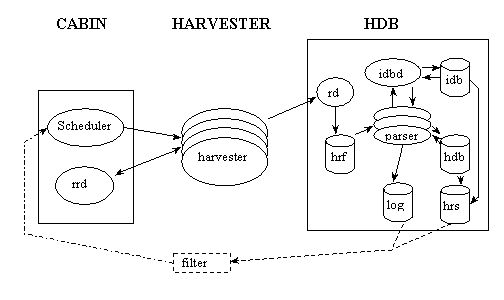
You are strongly recommended to visit the Combine home page http://www.lub.lu.se/combine to get a general overview before trying to install and run Combine. Note that some information on the Combine home page may be a bit out of date. Installing and running Combine Before you start, make sure you have:
Installation
Configuration
Running Combine Note that this example is intended to show what a Combine session looks like and is therefore run by hand.
Now what? If everything went fine, there should be be a file entry with a 'rec' suffix for each harvested Web page under the 'COMBINE/hdb/' directory. Take some time to browse the directories to see what has happened during your first Combine session. In order to harvest all interesting links that resulted from the this session, simply type: 'bin/new-url.pl | bin/selurl.pl | bin/jcf-builder-uniq.pl | bin/sd-load.pl' People who are more interested in getting things done rather than wasting time with low-level Combine details may irritably ask themselves: 'Isn't there any high-level interface available to all this nonsense?' Fortunately there is. Browse the html document cje/cje.html and find out how to install and run the Combine Job Editor. Note that you need a Web server to take full advantage of this package. Zebra and Z39.50 Zebra is an indexing system and a retrieval engine attached to a Z39.50 server. The following introduction to Z39.50 comes from a document at Indexdata describing Zebra.
The quotation above should encourage you to believe that Zebra will somehow index and answer Z39.50 queries on, say, the stuff that Combine recently fetched from the Web. Installing and running Zebra Installation
Configuring and running Zebra
The Europa Gateway Now is a good time to think about how to make our data publicly available. Since none of the most common Web browsers supplies a Z39.50 client we must have a Web interface to query our installation with HTTP requests. Visit http://europagate.dtv.dk/cgi-bin/egwcgi/80442/tform.egw and complete the three first fields of the form. Leave the others to their default values. Press 'submit'. Now search for the nickname that you just gave your name server. Enjoy! |
||||
|
Core skills
|
|
|
Anyone interested in setting up a vanilla-flavoured information gateway should be familiar with UNIX and its development environment in general. Knowledge of Perl-style regular expressions will make things a bit simpler. Programming skills and fluency in Perl are necessary for configuring an information gateway to fit a specific purpose, tuning performance and so on. |
|
|
Staff effort
|
|
|
Anyone who has the core skills listed above will be able to set up and configure a first gateway in under a week. With some experience it could be done in two hours. Experience shows that the maintenance of a gateway takes about four hours a week. |
|
| References
|
|
References
|
|
| Credits
|
|
|
Chapter author: Fredrick Rybarczyk |
|
| << P R E V I O U S | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | N E X T >> |
| Go to the table of contents |
| Return to: Handbook Home DESIRE Home |
Search | Full Glossary | All References Last updated : 20 April 00 |
Contact Us © 1999-2000 DESIRE |