| Search | Help |
|
Target audience
|
|
|
Section 3 of this handbook is aimed at gateway staff responsible for technical implementation - Internet specialists who will manage the hardware and software and implement new technical features. It aims to cover the important decisions that need to be made when setting up a new gateway (such as setting up the system and implementing the user interface) but also covers issues that arise in the day-to-day running of an existing gateway (such as running a link checker). Each chapter offers some background, practical tips and hints, key references, a glossary, case studies and examples. Watch out for the |
|
|
Contents
|
|
|
Section 1 : Strategic Issues Section 2 : Information Issues managers Section 3 : Technical Issues
|
|
|
|
||||
|
||||
|
Introduction
|
|
|
This chapter provides detailed information about the hardware and software that you would need in order to set up and run an Information Gateway using the ROADS and/or Combine software. |
|
|
Background
|
|
|
The Systems Requirements Overview chapter gives an introduction to the systems-related issues which managers need to consider when setting up and running an information gateway. This chapter provides more detailed technical information about the specific software and hardware requirements that you will need to meet. It does not consider all the issues raised in that chapter. You are referred to any good UNIX systems administration book for areas not covered in detail here, since security, performance, backing up data and so on are all issues that are relevant to running any network service! |
|
|
Software and hardware requirements
|
||||||||||
|
General requirements In order to run an information gateway you will need:
Don't forget about issues such as software and hardware support (and the fact that they may cost money) and think about what you are going to do when something breaks. Think about backing up your software, configuration and data. You may need a local tape drive for this or, if your organisation supports it, there may be a centralised archiving facility which you can take advantage of. ROADS requirements On top of the general requirements listed above, the current release of the ROADS software (version 2) requires:
In order to run the link checking tool and its associated report generator, you will need 'libwww-perl-5', which may be obtained from CPAN.
Combine requirements For the Combine software, you will need:
These are in addition to the general requirements listed above.
|
||||||||||
|
Glossary
|
|
|
CGI - Common Gateway Interface - A standard for running external programs from a World-Wide Web HTTP server. CGI specifies how to pass arguments to the executing program as part of the HTTP request. It also defines a set of environment variables. Commonly, the program will generate some HTML which will be passed back to the browser but it can also request URL redirection. (definition from The Free On-line Dictionary of Computing) |
|
| References
|
|
|
All Engineering, http://www.lub.lu.se/eel/ae/ Apache, http://www.apache.org/ BerkeleyDB, http://www.sleepycat.com/ Combine, http://www.lub.lu.se/combine/ CPAN, http://www.sn.no/libwww-perl/ Cygnus, http://www.Cygnus.com/ GNU, http://www.gnu.org/ Linux, http://www.linux.org/ Perl, http://www.perl.com/ ROADS, http://www.ilrt.bris.ac.uk/roads/ Sleepy-Cat Software, http://www.sleepycat.com/ SOSIG, http://www.sosig.ac.uk/ AE. Frisch, Essential System Administration (2nd ed.) (ISBN: 1-56592-127-5) M. Loukides, System Performance Tuning (ISBN: 0-937175-60-9) |
|
| Credits
|
|
|
Chapter author : Andy Powell |
|
|
Introduction
|
|
|
The chapter entitled User Interface Design introduced the major issues in the design of Web interfaces and in the collection of data to help inform a user interface design specification. The present chapter will look in more detail at those issues which are particularly relevant to the design of information gateways. Although some of the answers to the questions discussed here will be determined by your choice of software for running your gateway, the following points should still be considered before committing your institution to a particular solution. |
|
|
Background and Overview
|
|
|
The 'user interface design' chapter reviews the reasons why good interface design is necessary. However, there are important issues to consider which result from the limitations of the Web and HTML as a presentation tool and formatting language respectively, as well as from inconsistencies in the capabilities of different clients and the machines they run on. Both of these factors can cause problems in the attempt to realise your design. Problems of the first sort can usually be solved with a little ingenuity on the part of the Web designer, together with the use of helper technologies such as server-side scripting and stylesheets. The second type of problem is related to accessibility and usability issues and is covered in the chapter 'Accessibility and usability'. This chapter will therefore describe the approaches to implementing information gateway design that have been found to be of practical value within the gateways produced as a result of the work of the DESIRE projects, together with the results of their continuing experimental development. |
|
|
Recommendations
|
|
|
General Web design issues Many of the issues relating to good design practice for Information Gateways are common to all Web sites and have been covered in the User Interface Design chapter. Look 'n' feel The look of the site as a whole is best managed with mechanisms that allow for easy global control of style and content. Cascading Style Sheets (CSS) are an obvious choice, although care should be taken to test these against a variety of browsers and browser versions; there is still some incompatibility between Netscape Navigator and Internet Explorer and style sheets will not work on early versions of either. It is consequently vital to check your site on a number of different browsers to see how much your style sheets degrade on earlier versions. A useful online resource describing differences between various browser CSS implementation bugs is 'CSS Bugs and Workarounds' An additional mechanism for adding common elements to the site's pages is the use of Server-Side Includes (SSIs). These provide an excellent way to add components such as navigation bars (or style sheet references), as well as other common features such as feedback links and site logos, to sets of pages within the site. They work by using special tags which can be added to the HTML of a page and which cause the server to insert standard content at those locations. However, since the server needs to parse each of these pages before sending them on to a client, SSIs will reduce server performance. Both of these methods can also be applied to the display of search results, which will consist of pages generated on the fly (see the section 'Presenting search results'). Frames or no frames? There is some controversy over whether frames should be used in Web sites (e.g. 'Why frames suck most of the time'). As a means of enhancing navigation about a site, they can be very effective if used carefully; for instance a single frame down one edge could contain links to the various sections of the site. They can also make it easy for the user to return to your site having selected a link from their search results, since the remote site can be displayed within a frame. However, the navigation mechanisms can be provided as easily with SSIs; and the frames technique is generally frowned upon due to the problems of bookmarking, the copyright issues that arise from displaying a remote site within your own, and the reduction in screen space that results. There is also the potential problem of 'frames within frames' if the remote site also uses them. |
|
|
Design implementation issues specific to information gateways
|
|||||||||||||
|
Apart from general Web site design considerations, a number of interface issues need to be addressed which relate specifically to the nature of an information gateway. The main challenges involved are those of informing users what information the gateway contains and of enabling users to search that information sufficiently well to obtain the results they require. A third consideration concerns the manner in which search results are displayed to the user. It should be borne in mind that many users are not expert at searching databases and may not even be very familiar with the structure of the subject covered by the gateway. These are problems which have been faced by information professionals ever since the introduction of end-user searching with the development of CD-ROM databases. This section will look at these specialised user interface design issues. Informing the users about the gateway Our user studies have shown that most gateway users do not understand the difference between information gateways, directory services such as Yahoo! or search engines such as Alta Vista. It is also clear that few users make use of any search engine's full functionality. It is therefore important to provide sufficient text to explain what the gateway consists of and how it works, including its aims and policies, whilst accepting that most users do not like reading much text from the screen and that they should be presented with an uncluttered and simple looking interface which will not intimidate them. The usual attempt to solve this apparently impossible task is to provide information in the form of 'help' files but these are also unlikely to be read by the majority of users without some encouragement. Methods which may have more success include:
The search pages of the Social Science Information Gateway (SOSIG) and of OMNI demonstrate different methods of linking to 'help' information. The search interface Here also the main problem with presenting an interface to a search engine lies in making the full functionality of the engine available to the user in such a way that they can understand and use all its features without being intimidated. The usual approach is to provide two interfaces: one for simple searching and one containing the more advanced features. The search functionality available will obviously depend on the database and application software chosen to run on the catalogue, but advanced features will usually include options such as Boolean searching (may be implemented as all or any of terms in the query), phrase searching, searching by field (title, keyword, resource type, date range, etc.), case-sensitive searching and various methods of truncation or stemming. The usual way for the user to send in their search terms and option choices is by means of a typical HTML form. The selection of choices may be made with any of the standard HTML form options: radio buttons, checkboxes or pull-down menus. A common way of providing a 'simple' search interface is to provide default values of these options as 'hidden' values in the HTML form code. Unfortunately, experience from general Web search engines (e.g. http://www.useit.com/alertbox/9707b.html and http://www.useit.com/alertbox/9707b.html) and information gateways shows that advanced features are seldom used; for example, SOSIG has under 10% of its searches made from its advanced search page. This may be because users fail to understand their usefulness or are simply put off by a link that says 'Advanced search'. Help features, as described above, can ease this problem, but the interface designer should be aware of this issue when designing any 'advanced' search page. See the SOSIG advanced search page. Presenting Search Results It is useful to provide users with the alternatives of displaying results by title alone or giving the full description, possibly including other fields such as keywords. A third option might be to display the full set of metadata contained in the record. With 'titles only' selected, the full set of results can be displayed; when displaying full record details it is necessary to limit the length of the pages produced, otherwise the files transmitted can be very large, take too long to download, and require the user to do too much scrolling. Two methods of achieving this are by placing a limit on the number of results that will be displayed, requiring the user to further refine their search, or by displaying results on a number of separate pages.
With sets of data containing a few thousand records, the former method is quite practical, but becomes less so as the number of records in the database increases resulting in a corresponding increase in the average number of hits produced by a search. The average number of hits produced should therefore be monitored and the limit adjusted accordingly so that the server refuses only a small proportion of searches. Any such refusal to transmit too large a results set should be combined with mechanisms for narrowing the search, perhaps with a link to the advanced search page or to a thesaurus (see below). Alternatively, only the first portion of the results could be displayed, provided that some sort of ranking mechanism were being used to ensure that the most relevant results were shown (see below). The other option is to divide the results set over several pages. Whether results can be transmitted in this manner will depend on the search application used (for example, Z39.50 permits this, but Whois++ does not). A ranking mechanism is also useful with this method. It is usual to rank the results of keyword searches to ensure that the most relevant records come at the top of the list. This is usually accomplished with an algorithm which looks at the frequency with which search words appear in the records, with weightings applied depending on the location of the term (e.g. terms in the title, first paragraph and metadata fields will have a high weighting factor). It may be possible to amend or replace an existing ranking algorithm, perhaps by adjusting the weightings or by introducing factors based on user preferences (such as educational level of material or resource type), depending on what information is available in the records. You might also consider including a few easy to implement but very useful things in your search results pages:
(after Rosenfeld and Morville, 1998, p. 121) Browsing the catalogue The majority of information gateways provide browsing access to their collections as well as keyword searching. This is achieved by manually (or automatically) classifying individual resources according to a hierarchical classification scheme. Records for resources with the same class number (they may have more than one each) are displayed on the same page, with pages structured according to the classification scheme hierarchy. It is not usual to display the class numbers themselves, since these are of little interest to users, but to display only the title of the section.
There will need to be hypertext links between the different sections of the classification scheme structure, including links to parent, child and possibly 'related' sections. Simple HTML hypertext links can be used to represent the structure of the scheme, but it is important that the design enables easy navigation without the user's getting lost. 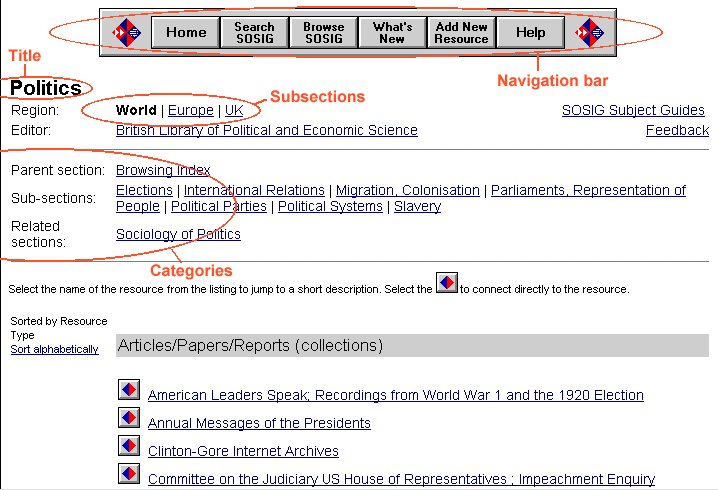 Depending on the facilities offered by the application software, the browse pages may be generated on the fly or periodically generated with a script; the latter method is used by the ROADS software. The script that generates the page will in many cases simply list the resources in alphabetical order but can also be used to group or filter them according to some other criterion such as resource type or country of origin. With a periodically generated set of pages, these latter options can be implemented simply by producing separate pages for each possible view. To enable the records to be split up into the different browse sections, a search using a class number field is made, or else the records themselves can be stored in directories whose hierarchical structure corresponds to that of the classification system. Combining searching and browsing Browsing and searching can also be combined to allow a simple search to be made from within the browse pages. This facility may offer the option of searching only those resources listed within the currently viewed classification section and all child sections, rather than the database as a whole. One method of accomplishing such a search is to hold the records in a file system whose hierarchical structure mirrors that of the classification scheme and restrict the records searched to those within the current directory plus child directories. An alternative approach is to perform a keyword search for the class numbers themselves in addition to the user's search terms. This can be problematic, however, as the search can end up involving a large number of child sections, requiring a complicated Boolean OR search that inevitably slows down the search engine. This problem may be overcome if the class numbers permit meaningful truncation or, if the notation of the classification system is not constructed in this manner, an alternative, hidden representation of the class numbers could be devised for the purpose which did permit it. Cross-searching and cross-browsing issues Methods of enabling the cross-searching and cross-browsing of Information Gateways are given in the chapter on Interoperability. However, there are a number of issues concerning the way that cross-searching and cross-browsing are presented to the user. Firstly, there is the question of whether a cross-searching facility should be made obvious to the user or kept hidden. If the mechanism is made open, how should it be presented to the user in a way they can understand? It would certainly be useful to provide information on each gateway concerning scope and selection criteria and a mechanism for selecting which gateways will be searched. With cross-browsing, there is also the question of what is actually meant by the term. One approach (used by the Social Science Information Gateway) is to enrich the holdings of one catalogue with links to the records of one or more other catalogues, the links being placed in the browsing structure alongside references to local records. An alternative approach to cross-browsing is simply to insert links within each browse section to the equivalent sections of other gateways. The user is then actually browsing across catalogues.
A further issue connected with the presentation of results of cross-browsing and searching concerns how or whether individual records should be differentiated by their origin. This could be done with additional text or copyright declarations or by the use of different icons. But this may be considered unnecessary (as far as the user is concerned, though perhaps necessary because of intellectual property rights considerations) and potentially confusing. A discussion of how cross-browsing may be achieved is given in the Interoperability chapter.
The thesaurus interface The Subject indexing and classification chapter discusses the issues involved in choosing a thesaurus for enhancing searching. In most cases an existing thesaurus relevant to the subject coverage of your information gateway will have been chosen and a local copy obtained (subject to agreements with the copyright holder).
To ensure that terms selected from the thesaurus produce useful results from your catalogue, we recommend that the local copy be a subset of the full thesaurus, which includes only those terms used in your catalogue. This can be accomplished by periodically running a script which compares the thesaurus terms against the catalogue's index. A decision will have to be taken as to whether the controlled terms from the thesaurus will be searched against all text in the catalogue records or restricted to terms in a keyword field. It is likely that the software for the local copy of the thesaurus will have to be created in-house. It should allow easy navigation through the hierarchy of terms and ideally allow searches of the catalogue to be performed automatically from those terms selected by the user.
A useful feature to add is the option of searching for the selected term together with all 'child' terms - a feature often known as an 'explode' option. As with searching by keyword within the browse sections of the catalogue, this can involve a complicated Boolean OR search, which is unacceptably slow. Similar techniques to those described in the section on combined searching and browsing could possibly be used to remedy this; for instance, by using an alternative representation of the keywords which could be used with truncation. As with the catalogue itself, it will usually be possible to browse through the hierarchical structure of the thesaurus as well as to search it by keyword. There may also be an alphabetical index of terms with links to the thesaurus. Browsing the thesaurus can be accomplished with hypertext links between related terms, with parent, child, related and non-preferred terms listed with the currently selected term. An alternative way to use the thesaurus for access to catalogue records is to produce a list of all records that contain the currently selected term. This turns the thesaurus into an alternative classification system. It is quite common for users to become confused and to believe they are actually searching the catalogue rather than the thesaurus; hence it is necessary to ensure that the thesaurus has a very different look and feel from the catalogue itself. See the example from OMNI below for an illustration of this.  The cataloguing interface All the interface implementation issues discussed so far concern the users of the catalogue. However, you also need to consider the way in which the cataloguing interface is implemented in order to ensure efficient data entry by the cataloguers of the system. As with many other implementation issues, the cataloguing interface will depend largely on the application being used. The following features should be considered when deciding on a system or designing one in-house:
|
|||||||||||||
|
Glossary
|
|
|
Boolean searching - The use of use the "Boolean operators" (AND, OR, NOT) in keyword searching to combine keywords and so control the resulting matches and make more precise searches. |
|
| References
|
|
|
Biz/ed, http://www.bized.ac.uk/ CSS Bugs and Workarounds, http://css.nu/pointers/bugs.html HASSET, http://dasun1.essex.ac.uk/services/zhasset.html OMNI, http://www.omni.ac.uk/ SOSIG, http://www.sosig.ac.uk/ W3C Cascading Style Sheets, http://www.w3.org/Style/css/ L. Rosenfeld & P. Morville, Information Architecture for the World Wide Web (O'Reilly, 1998). Jakob Nielsen'Why frames suck most of the time' |
|
| Credits
|
|
|
Chapter author: Phil Cross, Martin Belcher |
|
|
|
||||
|
||||
|
Introduction
|
|
|
The issues of good accessibility and usability are closely linked. Their importance has been emphasised in previous chapters of the handbook. How can these issues be best tackled and implemented in the development of a new gateway or the modification of an existing one? |
|
|
Accessibility and usability for your gateway
|
|
|
The accessibility and usability criteria of your gateway should have been drawn up after some degree of user consultation. Ideally, the user consultation will have produced a user interface design specification; The specification should contain particular information such as the gateway name, section division naming (if appropriate), structure and information architecture. Guidelines or parameters such as maximum page size (pixels and/or bytes), maximum download times, colour palette size and makeup, colour scheme and use of images will also form part of the specification. An ideal end result might be a document in the form of a checklist, against which a design can be developed and checked. Remember that a checklist which contains too many items can be unusable in itself. Test a prototype version of your checklist to see if it is usable, before rolling it out to all developers. A design specification will probably be divided into several areas. Usability issues What usability issues will the gateway conform to? Guidelines here might be:
Site structure and navigation It seems obvious, but some of the key problems with Web sites arise from the naming of sub-sections and the associated navigation of them. Fortunately, information gateways have common key sections which can easily be worked into a navigation system and which are almost universally understood (subject-specific and specialised gateways may differ in this area and so may be tailored to the user community). Section names often include:
Accessibility issues What accessibility criteria will the gateway conform to? Fortunately, a definitive set of accessibility guidelines already exists in the form of a W3C Recommendation: Web Content Accessibility Guidelines 1.0. It would save time and effort to adopt some or all of these official guidelines. The exact guidelines that are used may vary from gateway to gateway, as there are many recommendations and it may not be realistic to implement them all. Luckily, the guidelines have been prioritised in a way that makes it easy to see which accessibility issues have the greatest influence on potential users:
(see 'Disabled Accessibility: The Pragmatic Approach') You might decide only to use items in the 'Priority 1' checklist and a selection of those from the lower priority groups, for example:
|
|
|
Implementing accessibility guidelines
|
||||
|
The simplest way to implement and check that your gateway meets its accessibility and usability requirements is to use a simple 'checklist' during development of the interface. Developing the user interface as a series of templates, separated from the technology of the gateway, makes changing aspects of the interface much easier. As the interface develops it can be continually checked against the checklist of requirements. When a gateway's interface is complete, it is often worth stating that the site conforms to certain guidelines (e.g. HTML 4.0, Bobby Approved, Web interoperability); however, do not do this on your most commonly accessed pages (e.g. the home page or the search page) but rather confine this information to an 'about' section or page. Validating your gateway's accessibility
|
||||
|
Usability into the future
|
||||
|
It is worth noting that Web-related technologies change, users change and information changes. However, seldom do any of these variables change at the same time. The result is that you should always be aware that the criteria for usability and accessibility are not set in stone. Along with other aspects of the gateway, these criteria should be reviewed from time to time and, if need be, adjusted to meet changes and developments. It should be noted that users rarely change as quickly as everything else around them! Caution is therefore advisable when implementing any user-side technological changes.
|
||||
|
Glossary
|
|
|
Accessibility - the characteristics of Web content and whether or not it is accessible to people with disabilities |
|
| References
|
|
|
Bobby, http://www.cast.org/bobby/ Disabled Accessibility: The Pragmatic Approach Jacob Nielsen's Alertbox Column List of Checkpoints for Web Content Accessibility Guidelines 1.0 L. Rosenfeld & P. Morville, Information Architecture for the World Wide Web (O'Reilly, 1998). J. M. Spool et al., Web Site Usability: A Designers Guide (Morgan Kaufmann Publishers Inc., 1999). W3C, Web Content Accessibility Guidelines 1.0 |
|
| Credits
|
|
|
Chapter author: Martin Belcher, Phil Cross |
|
|
|
||||
|
||||
|
Introduction
|
|
|
This chapter provides a starting point for technical specialists who are considering using harvesting, indexing and automated metadata collection within their information gateway. An information gateway which works like this consists of three separate mechanisms:
The main software components used in the DESIRE II project are reviewed. The rest of this chapter describes how to glue the different pieces together into a running environment that can accommodate further development. |
|
|
Background
|
|
|
The core function of an information gateway is to make bibliographic records available for advanced searching. The ANSI/NISO Z39.50 protocol is specially designed to support very detailed request and retreival sessions. That is why the Desire project uses the Zebra server software which implements that very protcol. Since ANSI/NISO Z39.50 isn't very widely supported (none of the major Web browsers provides a client) we need to use a gateway. The gateway's main functionality is to channel requests passed via HTTP to a Z39.50 server and return an appropriate response. It also has to keep track of all the different sessions for all users who access the gateway. Finally, we obviously should have a robot to collect the Web resources in the first place. There are many robots available, but we need one that can deal with our particular interest in metadata as well as our need to adjust robot output in a way that makes it easily available to the Zebra server. Combine fulfils both these requirements. |
|
|
Harvesting and Combine
|
||||
|
The harvesting metaphor was coined because of the strong similarities between the automated collection of Web resources and real-world harvesting. Both of these tasks raise three key issues:
The first question is concerned with how best to discover Internet resources and is primarily a matter of manual selection. Those aspects are described in a separate chapter. It does, however, highlight an important problem that begs for computerised support. A harvester works very well on a field of corn but it performs poorly in other contexts, for instance when we're looking for rare mushrooms in a forest. We simply cannot take everything and then sift the mushrooms from the wood, grass and pebbles. A similar line of reasoning applies to a Web robot. It would be a huge waste of time and resources to make a robot crawl around the entire .com domain in order to harvest any page concerning the sale of fountain pens. While it is possible to employ subject specialists to detect valuable Web resources and librarians to catalogue them, such an approach is relatively expensive. For this reason it is tempting to design a Web robot that, when given a promising starting point, is able to select which trails to follow.
The last two questions are easier to approach from the point of view of an information analyst who wishes to design a Web robot so we'll dispense with the agronomics. Instead we shall turn our attention to how the Combine system is designed to serve as an integral part of an information gateway. Combine is an open, metadata-aware system for distributed, collaborative Web indexing and it is freely available. It consists of a scheduler, a couple of robots, and receivers that process and store robot output. 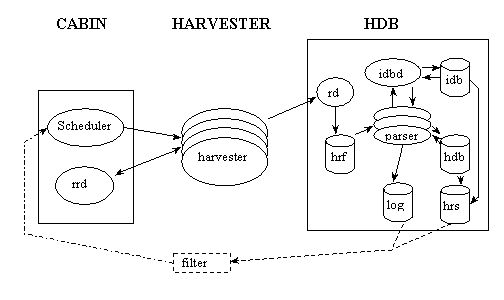
You are strongly recommended to visit the Combine home page http://www.lub.lu.se/combine to get a general overview before trying to install and run Combine. Note that some information on the Combine home page may be a bit out of date. Installing and running Combine Before you start, make sure you have:
Installation
Configuration
Running Combine Note that this example is intended to show what a Combine session looks like and is therefore run by hand.
Now what? If everything went fine, there should be be a file entry with a 'rec' suffix for each harvested Web page under the 'COMBINE/hdb/' directory. Take some time to browse the directories to see what has happened during your first Combine session. In order to harvest all interesting links that resulted from the this session, simply type: 'bin/new-url.pl | bin/selurl.pl | bin/jcf-builder-uniq.pl | bin/sd-load.pl' People who are more interested in getting things done rather than wasting time with low-level Combine details may irritably ask themselves: 'Isn't there any high-level interface available to all this nonsense?' Fortunately there is. Browse the html document cje/cje.html and find out how to install and run the Combine Job Editor. Note that you need a Web server to take full advantage of this package. Zebra and Z39.50 Zebra is an indexing system and a retrieval engine attached to a Z39.50 server. The following introduction to Z39.50 comes from a document at Indexdata describing Zebra.
The quotation above should encourage you to believe that Zebra will somehow index and answer Z39.50 queries on, say, the stuff that Combine recently fetched from the Web. Installing and running Zebra Installation
Configuring and running Zebra
The Europa Gateway Now is a good time to think about how to make our data publicly available. Since none of the most common Web browsers supplies a Z39.50 client we must have a Web interface to query our installation with HTTP requests. Visit http://europagate.dtv.dk/cgi-bin/egwcgi/80442/tform.egw and complete the three first fields of the form. Leave the others to their default values. Press 'submit'. Now search for the nickname that you just gave your name server. Enjoy! |
||||
|
Core skills
|
|
|
Anyone interested in setting up a vanilla-flavoured information gateway should be familiar with UNIX and its development environment in general. Knowledge of Perl-style regular expressions will make things a bit simpler. Programming skills and fluency in Perl are necessary for configuring an information gateway to fit a specific purpose, tuning performance and so on. |
|
|
Staff effort
|
|
|
Anyone who has the core skills listed above will be able to set up and configure a first gateway in under a week. With some experience it could be done in two hours. Experience shows that the maintenance of a gateway takes about four hours a week. |
|
| References
|
|
References
|
|
| Credits
|
|
|
Chapter author: Fredrick Rybarczyk |
|
|
|
||||
|
||||
|
Introduction
|
|
|
This chapter provides a brief overview of some issues surrounding the provision of personal profile services for Information Gateways. It is beyond the scope of this document to offer a comprehensive account of these complex issues. Instead, a brief summary of major points is provided alongside pointers to more detailed treatments available online. |
|
|
Why Profiles?
|
|
|
User profile services are a natural extension to the subject gateway approach. Subject-themed Information Gateways provide a focal point for broadly defined subject communities. Through the addition of user profile facilities, broadly-based gateways can begin to provide more specific 'views' into their information services. This is particularly important where a gateway's target audience includes multiple smaller communities. For example, a Social Science service such as SOSIG may have information appropriate for the Economics, Psychology and Law subject areas. Individuals in these professions may think of themselves as economists, psychologists or lawyers rather than as social scientists. A broadly based Social Science gateway that covers these topics (amongst others) might therefore benefit from an architecture which allows community specific or personalised views into a sub-set of the available resources. User profiles, which we might loosly define here as 'data structures that describe the properties of users', are an essential component of such a system since they allow a service to cross-reference information resources against user interests. |
|
|
Personalisation
|
|
|
The notion of a 'personalised' interfaces to Web content has become commonplace. There are challenges involved in the creation of such interfaces, but these typically share a common component: personal profiles. As used here, 'personal profiles' refers to the practice of describing individuals and various of their properties in a database for the purpose of improving their access to networked information resources. For example, a profile might store name and address details, home page URL, URL of an online image of that person, alongside details of their interests. |
|
|
Characterising User Interests
|
|
|
While there are no established standards for doing this, a simple guiding principle is to attempt to align the subject classification of documents and other 'discoverable' resources with user profile 'interest' classifications describing the subject or subjects that some user is interested in hearing about. For example, an information gateway targeted at the Economics community might adopt the JEL (Journal of Economic Literature) subject scheme both for user profiles and for classification. The SOSIG Grapevine service, similarly, has used the UDC subject scheme for personal interest profiling, to facilitate easy cross referencing with SOSIG catalogue records. Many of the observations made in this handbook concerning the value of formal classification schemes and controlled vocabularies in the context of document description are also of relevance in the field of user profiling. There are, however, some differences. If complex structured vocabularies are to be used to allow users to describe their interests, a number of challenges arise for Information Gateway architects. User Interface: Multiple subject schemes: Multiple interests: |
|
|
Authentication, Trust and Standards
|
||||
|
For an information gateway to offer personal profile based services, it is necessary for the service to have one or more mechanisms to establish the identity of users. There are a range of options here, from a simple stand-alone database of username/password pairs to more sophisticated cryptographic solutions. Gateway providers should be aware that there is as yet no widespread 'right answer' to this problem. Deployment of cryptographic (digital signature) technologies for this is at an early stage. Simpler username/password approaches (particularly when the default non-encrypted 'Simple authentication' HTTP authentication protocol is used) have their own problems. Users will frequently forget their passwords, and are known to be reluctant to go to the trouble of logging in to an authenticated service unless there is a clear benefit to doing so. It is important to establish both formal and informal trust relationships with users when building a personalised, authentication-mediated Information Gateway. A formal 'privacy statement' for your service is a necessity. Users should know exactly what data you will be holding about them, and the purposes to which it will be put. The Platform for Privacy and Preferences (P3P) work of the World Wide Web Consortium (W3C) is a relevant standard here. P3P provides a common vocabulary for making such statements, both in simple natural language and in a machine-processable XML/RDF vocabulary. The idea here is to facilitate automatic negotiation between 'user agents' (i.e. Web browsers) and Web services such as information gateways. The current Web model for acquiring user profile information from users usually involves the user completing a Web form. Uses are often reluctant to do so, both due to lack of trust or knowledge regarding the remote service, or because it is simply a boring and repetitive task. The combination of metadata standards such as P3P, vCard and XML/RDF promises to make this task easier. vCard is a simple standard which specifies a common set of fields for personal profile data; in this sense it plays a similar role to that played by the Dublin Core element set in document description. A P3P-aware browser and server should be capable of discussing, on behalf of their human counterparts (end user, service provider) the data fields requested by the server and the applications it will be acceptable to use these for. Whilst P3P is not yet widely deployed, Information Gateway services should be aware that such facilities are a likely development, and that their potential for service enhancements may be significant. For example, if P3P succeeds, Web services will be able to automatically ask for subject-interest information about users browsing their site.
|
||||
|
Directory Services
|
|
|
One possible technology applicable to Information Gateway user profile services is LDAP, or more broadly, 'white page' directory services. LDAP is a derivative of the older X.500 standard for representing personal data in a set of networked databases. LDAP does not address problems such as the classification of user interests, but does provide a widely implemented standard for representing name, address and contact detail information. Whether a directory-based approach, rather than a privately managed database, is appropriate will depend on the nature of your application. Where profile information will be exploited by a number of loosely connected Information Gateways, LDAP may be an attractive solution. |
|
|
Legal Issues
|
|
|
Any computer-based service which stores data about individuals should take legal advice about their practices, and in particular about the implicit or explicit contracts that they enter into with users. It is beyond the scope of this handbook to offer further guidance here, other than to say that the full complexities of the international environment of the Web have yet to be worked through in court. Different countries have varying laws regarding the management and storage of personal profile data; service providers should consequently proceed with caution when making such systems available to an international user base. |
|
|
Glossary
|
|
|
LDAP - Lightweight Directory Access Protocol |
|
| References
|
|
|
Grapevine, http://www.grapevine.sosig.ac.uk/ M. Wahl, T. Howes & S. Kille, RFC 2251, Lightweight Directory Access Protocol
(v3) (Internet Engineering Task Force, Network Working Group, December 1997).
|
|
| Credits
|
|
|
Chapter author: Dan Brickley |
|
|
|
||||
|
||||
|
Introduction
|
||||
|
No single information gateway will be able to describe each and every relevant Internet resource, even if it is limited to a relatively small subject area. Therefore, as the Internet continues to grow, gateways will need to co-operate (and interoperate) with each other to create distributed systems with wide geographical and linguistic coverage. Place (1999) suggests that the international library community is well placed to take up this challenge. She also notes that a collaborative network known as IMesh will provide an open forum for exchanging ideas and technology. Indeed, the consistent use of existing standards and technologies already permits a large amount of inter-gateway collaboration. A lot of technical effort has gone into building interoperability between search protocols and metadata formats and into developing gateway software that is able to cross-search more than one gateway.
This chapter will not explain in technical detail how to implement interoperability features in a gateway, but will provide an overview of the various issues surrounding gateway interoperability. |
||||
|
Background
|
|
|
In a computer science context the term 'interoperability' is used to refer to the transparent management of different applications and software. In an information gateway context, interoperability generally means one of two things:
These two different challenges require slightly different solutions. Where the same protocols and metadata formats are in use, ensuring interoperability is usually a matter of making sure that each gateway is set up in a consistent manner and has the correct interfaces. For example, it should be relatively easy to ensure that all services based on the Whois++ search and retrieve protocol (e.g. services based on the ROADS software toolkit) can be cross-searched. Interoperability, in these circumstances, becomes less of a technical problem and more a matter of the consistent use of metadata formats and their related content standards (e.g. cataloguing and subject indexing). Where services are based on a variety of protocols and metadata formats, however, these non-technical problems remain - indeed, they are usually more difficult to solve - but additional technical layers will also need to be developed, involving the production of inter-protocol gateways, 'middleware' and metadata crosswalks. In practice, however, information gateways tend to be based on a relatively small number of technologies, protocols and metadata formats, at least when compared with the whole information universe. This means that any work carried out on integrating several selected protocols and formats will be applicable in a number of different situations. |
|
|
Information gateways and interoperability
|
|||||||||||||||||||
|
Ensuring that information gateways are interoperable will generally require the consistent application of available standards. There are four main 'standards-based' factors affecting interoperability among information gateways:
Protocols Interoperability among information gateways requires the consistent use of relevant protocols. The most relevant protocols for gateways are LDAP, Whois++ and Z39.50. The Lightweight Directory Access Protocol (LDAP) LDAP (cf. e.g. RFC 2251) was developed as a simple alternative to the ISO X.500 protocol, a directory access protocol designed for providing access to distributed information about people (names, email addresses, telephone numbers, etc). Accordingly, most existing applications of LDAP are so-called 'white pages' services. However, there is no reason why LDAP cannot be used for other services, including information gateways.
Whois++ The Whois++ protocol was originally developed for directory services, to operate as a simple (template-based), distributed and extensible information lookup service (RFC 1835). Its extensible architecture, however, meant that its developers expected it to find applications in a number of other information service areas. Whois++ also provides a general architecture that is designed for the indexing of distributed databases and then applies that architecture to link together a multiple number of these Whois++ servers into a distributed, searchable wide-area directory service (RFC 1913). Unlike other directory protocols (e.g. X.500 or LDAP), Whois++ does not require a hierarchical representation of data space, but servers 'refer' the clients to other servers in a Whois++ 'mesh' (RFC 1914). Queries are routed through this mesh based on 'forward knowledge' held by one server about another. In Whois++, this forward knowledge is maintained using the Common Indexing Protocol (CIP). CIP is a protocol used between servers in a network to facilitate query routing, the 'act of redirecting and replicating queries through a distributed database system towards the servers holding the actual results via reference to indexing information' (Allen and Mealling, 1997). It is not part of Whois++ and indeed can be used with other protocols such as LDAP. CIP is based upon the concept of index summaries or centroids. A centroid can be considered as a summary of the structured information in a given server; for example, it could be a simple inverted index of the information contained within a database's templates. This can then be used, for (e.g.) query routing within a distributed database.
Z39.50 The Z39.50 protocol (e.g. Library of Congress, 1999) is a standard for information retrieval approved by the National Information Standards Organization (NISO) - a committee accredited by the American National Standards Institute (ANSI). It has also been recognised by the International Organization for Standardization (ISO), where it is known as ISO 23950:1998. The Z39.50 protocol allows client applications to search databases on remote 'target' servers and to retrieve relevant information. It therefore supports the retrieval of information from distributed remote databases (Turner, 1995). The first applications using it, for example software for distributed searching of library online public-access catalogues, were developed specifically for bibliographic data, but attribute sets can be defined to allow the protocol to work with many other types of data. For example, systems using Z39.50 have been developed for libraries, archives, museums and data archives.
Z39.50 has not been widely implemented by information gateways. However, there is a wider need to ensure that gateways can interoperate with other resource discovery systems (such as library OPACs, hybrid library systems) and different metadata formats. For these reasons, projects like ROADS have needed to address issues relating to gateway interoperability with Z39.50.
Metadata formats Metadata crosswalks Different information gateways will often use different metadata formats. For this reason there is a need for crosswalks (or mappings) between formats that can be used as the basis of interoperable systems (such as middleware) or for conversion programs. A number of inter-metadata crosswalks exist, many based on Dublin Core (RFC 2413). Core metadata formats are well placed to act as intermediaries for semantic interoperability between heterogeneous resource description models. Weibel (1997, p. 18) suggests that the promotion of a 'commonly understood set of core descriptors will improve the prospects for cross-disciplinary search by unifying related attributes'. He additionally suggests that an important approach to interoperability in a heterogeneous resource description environment would be to map many description schemas into a common set (such as Dublin Core) which would give users 'a single semantic model for searching'. A number of Dublin Core (DC) based mappings currently exist; for example, there are important crosswalks from Dublin Core to USMARC (Caplan and Guenther, 1996; Network Development and MARC Standards Office, 1997). Other people and organisations have also produced DC mappings for various other formats including TEI headers, the Nordic MARC formats (as part of the Nordic Metadata Project) and UNIMARC (for project BIBLINK). A collection of these metadata mappings is maintained by Day (1996). The ROADS project has produced metadata crosswalks between ROADS templates, Dublin Core, SOIF and the USMARC format. Metadata Registries Metadata formats require consistent application. This is particularly a problem with formats that are easily adaptable and extensible, such as ROADS templates or Dublin Core. It would be possible for an information gateway to modify (or customise) a metadata format so much that the service based on it would no longer be interoperable (cross-searchable) with other gateways. One solution would be to require all gateways to conform to an agreed set of metadata attributes. However this goes against the very flexibility that gateways require in order to provide a good service to their own users. What is needed is a way of recording current practice so that gateways can modify metadata formats in the knowledge of what other gateways have done and without the problem of 'reinventing the wheel'.
What are needed are extensible metadata registries which provide canonical definitions of all elements and also disclose local uses. These registries should be understandable by both humans and machines. ISO/IEC 11179:1997 - Specification and standardization of data elements is a formal standard for expressing the semantics of data elements suitable for registries, but few metadata registries based on this standard currently exist.
Content issues Cataloguing In practice, interoperability is not just dependent upon consistency in the use of the metadata format itself but is also dependent upon the consistency of the content contained within the format. For example, in the library community the MARC formats specify a framework for the description of bibliographic items while the content of MARC records will often conform to other standards, usually based on one of the International Standard Bibliographic Descriptions (ISBDs) or cataloguing rules derived from them. For this reason, the formulation of cataloguing guidelines will be an important part of the interoperability strategy of a gateway (e.g. Day, 1998). This will mean taking account of cataloguing practice in other gateways and the production of standardised cataloguing rules, considering such issues as:
Subject classifications Another content-based area where interoperability is likely to become an issue is in the application of subject information in the form of classification schemes and thesaurus terms. Classification schemes provide an information gateway with a browsing structure. It is possible that two or more distributed gateways could be combined to form a single service. Successful cross-browsing will depend upon the consistent application of the same classification scheme. Therefore, information gateways that want to facilitate cross-browsing should, wherever possible, use the same classification system. Otherwise, complex mappings will have to be produced to enable conversion between schemes. This may not be too difficult at the higher levels of a universal subject hierarchy but where any detail is involved it will become problematic because of theoretical, conceptual, cultural and practical differences between systems.
|
|||||||||||||||||||
|
Conclusions
|
|
|
It is important for all information gateways to consider interoperability issues. It is generally agreed that the way forward for information gateways is increased co-operation; successful information gateway co-operation will depend upon successful interoperability and in the consistent application of standards regarding such matters as protocols, metadata formats, cataloguing rules and subject classification schemes. Gateways can start to make immediate use of existing tools that promote interoperability and to build the technical links between distributed gateways that will form the basis of any future international co-operation. |
|
|
Glossary
|
|
|
ADS - Archaeology Data Service |
|
| References
|
|
|
AHDS gateway, http://ahds.ac.uk:8080/ahds_live/ IMesh, http://www.desire.org/html/subjectgateways/community/imesh Isaac Network, http://scout.cs.wisc.edu/research/index.html NHIK, http://www.aihw.gov.au/services/health/nhik.html ROADS, http://www.ilrt.bris.ac.uk/roads/ ROADS template registry, http://www.ukoln.ac.uk/roads/templates/ ROADS Z39.50 plugin, http://www.ilrt.bris.ac.uk/roads/software/zplugin/ J. Allen & M. Mealling, The architecture of the Common Indexing Protocol (CIP) (FIND Working Group, Internet-Draft, 18 November 1998). P. L. Caplan, & R. S. Guenther, 'Metadata for Internet resources: the Dublin Core Metadata Element Set and its mapping to USMARC', Cataloging and Classification Quarterly 22 nos. 3-4 (1996), 43-58. M. Day, Mapping between metadata formats (Bath: UKOLN The UK Office for Library and Information Networking, 1996). M. Day, ROADS cataloguing guidelines (Bath: UKOLN The UK Office for Library and Information Networking, 1998). P. Deutsch, A. Emtage, M. Koster & M. Stumpf, Publishing information on the Internet with Anonymous FTP (Internet Engineering Task Force, Internet Draft, September 1994). P. Deutsch, R. Schoultz, P. Faltstrom & C. Weider, RFC 1835, Architecture of the WHOIS++ service (Internet Engineering Task Force, Network Working Group, August 1995). P. Faltstrom, R. Schoultz & C. Weider, RFC 1914, How to interact with a Whois++ Mesh (Internet Engineering Task Force, Network Working Group, February 1996). J. Foster, M. Issacs & M. Prior, RFC 2007, Catalogue of network training materials (Internet Engineering Task Force, Network Working Group, October 1996). D. Greenstein & R. Murray, 'Metadata and middleware: a systems architecture for cross-domain discovery' in P. Miller & D. Greenstein, eds., Discovering online resources across the humanities: a practical implementation of the Dublin Core (Bath: UKOLN on behalf of the Arts and Humanities Data Service, October 1997), 56-62. ISO 23950:1998, Information and documentation - Information retrieval (Z39.50) - Application service definition and protocol specification (Geneva: International Organisation for Standardization, 1998). ISO/IEC 11179:1997, Information technology - Specification and standardization of data elements (Geneva: International Organisation for Standardization, 1997). J. Kirriemuir, D. Brickley, S. Welsh, J. Knight & M. Hamilton, 'Cross-searching subject gateways: the query routing and forward knowledge approach', D-Lib Magazine (January 1998). J. P. Knight & M. Hamilton, Overview of the ROADS software (LUT CS-TR 1010. Loughborough: Loughborough University of Technology, Department of Computer Studies, 1995). Library of Congress, Z39.50 Maintenance Agency [home page], (Washington, D.C.: Library of Congress 1999). C. Lukas & M. Roszkowski, 'The Isaac Network: LDAP and distributed metadata for resource discovery', Third IEEE Meta-data Conference, National Institutes of Health, Bethesda, Md., USA, 6-7 April 1999. P. Miller & D. Greenstein, Discovering online resources across the humanities: a practical implementation of the Dublin Core (Bath: UKOLN on behalf of the Arts and Humanities Data Service, October 1997). Network Development and MARC Standards Office, Dublin Core/MARC/GILS Crosswalk (Washington, D.C.: Library of Congress, 4 July 1997). E. Place, 'International collaboration on Internet subject gateways', 65th IFLA Council and General Conference, Bangkok, Thailand, 20-28 August 1999. ROADS project, CrossROADS (Bath: UKOLN The UK Office for Library and Information Networking, 1998). M. Roszkowski & C. Lukas, 'A distributed architecture for resource discovery using metadata', D-Lib Magazine (June 1998). F. Turner, An overview of the Z39.50 Information Retrieval standard (UDT Occasional Paper, 3. Ottawa: IFLA Universal Dataflow and Telecommunications Core Programme, 1995). M. Wahl, T. Howes & S. Kille, RFC 2251, Lightweight Directory Access Protocol (v3) (Internet Engineering Task Force, Network Working Group, December 1997). S. Weibel, J. Kunze, C. Lagoze & M. Wolf, RFC 2413, Dublin Core metadata for resource discovery (Internet Engineering Task Force, Network Working Group, September 1998). C. Weider, J. Fullton & S. Spero, RFC 1913, Architecture of the Whois++ Index Service (Internet Engineering Task Force, Network Working Group, February 1996). |
|
| Credits
|
|
|
Chapter author: Michael Day |
|
|
|
||||
|
||||
|
Introduction
|
|
|
Scalability is an issue that needs to be considered when designing any system for long-term data storage. It is not sufficient to design your system to meet current requirements; you also need to take into account (or at least be aware) how your collection of data is likely to grow in the coming years. A system that is perfectly adequate for storing, manipulating and providing access to a small number of records or data may be quite unable to cope if the amount of data increases by one or two orders of magnitude. This chapter will look at the problems and issues specific to subject gateways that arise because of such increases in database size and will consider approaches to dealing with these problems. |
|
|
Background
|
||||
|
At present, subject gateways tend to consist of no more than a few thousand records because of the manual effort required to select and catalogue Internet resources. Even a 'large' subject gateway typically has only about six or seven thousand records. This is very small in comparison with traditional online bibliographic databases. Consequently, the problems associated with storing and retrieving large collections of bibliographic data, such as recall and precision in searches and search engine functionality, have not yet been significant. It seems unlikely that individual subject gateways are capable of growing significantly in size, given current funding models. Only directories that have limited or no quality criteria, high levels of funding or possibly voluntary effort - such as Yahoo!, OCLC's NetFirst or the Open Directory Project - seem to be capable of producing manually-created databases with sizes of the order of hundreds of thousands of records. The likely method of growth for subject gateways seems instead to be via collaborative effort. There are two approaches to building a collaborative subject gateway. The first is for a number of different organisations to contribute records to a central database. The problems with such an approach are likely to be concerned with the size of the database, maintaining reasonable performance on a single machine and providing network access to it. The second approach is for each organisation to maintain its own database, allowing the end-user to search across one or more of them depending on the nature of their query. In some cases a combination of the two approaches may be appropriate. These methods allow a real or virtual increase in size of the collection of resources presented to the end-user.
We have also begun to see the creation of harvesting software which enables the automated indexing of Internet resources whilst retaining a degree of quality because of the ability to choose the seeding URIs for the robot. The first phase of the DESIRE project developed some harvesting tools that can be used in conjunction with the ROADS and Zebra software. Such mechanisms have the potential to create databases at least one order of magnitude larger than those of current gateways. This increase in size of the database presented to the end-user and the ability to pass a single search to a number of different databases produce new problems that need to be addressed.
|
||||
|
Scalability Issues
|
|
|
Overview Part of the scalability problem is concerned with interface and usability issues. These include the presentation of large results sets to the user, the means by which the cross-search paradigm is presented and the ranking or filtering of any results produced. Another part of the problem is concerned with the management of such collections: for example, the need for automated mechanisms for link checking and perhaps for detecting changes to sites that require their descriptions to be updated. Finally there are issues relating to the computer systems used to run the subject gateway service, such as the need for databases that can handle much larger collections of data. The rest of this chapter therefore consists of three sections; the first will look at user interface and usability issues, the second will consider administration and management issues and the third will consider the systems issues involved in maintaining large collections of records. User interface and usability issues With a relatively small database, the issue of precision in searching is not very important, since the user can scroll quickly through a results set to discover which are the most useful records. However, as the size of the database increases, so does the average number of records retrieved, and it then becomes much more difficult to select the most relevant and useful ones. This problem can be approached in two ways:
Here are some ways in which the precision of searches can be increased:
Displaying large results sets Typically, large results sets cannot be displayed on a single Web page. This is because of the time taken to retrieve the data and because of scrolling problems for the end-user. The ROADS software limits the total number of records which can be returned by a search but, as the size of the database increases, the proportion of searches resulting in 'too many hits' will also increase. In addition to reducing the number of hits returned, by increasing the precision of searches, it may also be sensible to investigate mechanisms for improving the way in which records are displayed. These may include:
Browsing larger collections (including cross-browsing) Most subject gateways provide a browsing interface to their data in addition to a search interface. Many of the issues raised above apply equally to the browse interface. For example, as the number of records in the database grows, the lists of records presented in the browse interface are likely to become too long to be shown on a single Web page. The browse interface is typically designed (at least in part) around the controlled vocabulary (classification scheme) for keywords described above. As the database increases in size, the number of records per section will also increase unless the granularity of the classification scheme is increased. Therefore, there are some design decisions that need to be taken concerning the depth and complexity of the classification scheme used.
It is worth noting that a combination of browse and search interfaces may help the end-user. This may be achieved by embedding a restricted search interface into each sub-section of the browse interface, returning results that are only applicable to that sub-section. Administration and Management Issues As the number of records in a subject gateway database increases, the techniques used to manage it may need to change. Manual checking of records is likely to be feasible for a small database, but who wants to check 7,000 records by hand? What about 50,000 records?! Some areas where automated checking of records may be possible are:
Systems Issues It is clear that as a database grows the amount of disk space it requires will also grow. Memory and CPU power requirements will probably also increase. It is possible that database software that copes with 10,000 records may not cope efficiently with 100,000 records. For example, there is some evidence that the file system based database software supplied with ROADS by default does not cope well with databases larger than about 50,000 records. In theory, ROADS allows you to plug in alternative back-end databases. However, it is not clear how many services are actively using this feature. There may also be performance problems associated with cross-searching large numbers of large databases. The searching system has to wait for results to come back from all the databases that it is searching. This may tie up network and other resources on that system. Research is currently being done within the DESIRE project into the areas of parallel searching and results interfaces which return results to the user as and when they become available. Findings in this area will be published on the DESIRE Web site. |
|
|
Glossary
|
|
|
DESIRE - Project funded under the Europena Union's Telematics for research Programme to enhance and facilitate Web usage among researchers in Europe (producer of this handbook) |
|
| References
|
|
|
Combine, http://www.lub.lu.se/combine DESIRE, http://www.desire.org/results/training/D8-2af.html OCLC, http://www.oclc.org/ Open Directory Project, http://dmoz.org/ SOSIG Harvester, http://www.sosig.ac.uk/roads/cgi/search.pl?form=harvester Yahoo!, http://www.yahoo.com/ |
|
| Credits
|
|
|
Chapter author: Phil Cross, Andy Powell |
|
|
|
||||
|
||||
|
Introduction
|
|
|
It is in the interests of all associated with the service to make reasonable attempts to future proof investment in the subject gateway. In this chapter we will consider how concern for future proofing can influence the gateway's decisions as regards hardware, software and content. Good decisions in these areas will provide a sound foundation for the future of the gateway. We will give a brief overview of some issues related to planning for the future in an area of rapid technological change and introduce some thoughts on how planning relates to decision making in the context of subject gateways. The continued existence of a gateway depends ultimately on a sound business model with assured income. The wider aspects of business planning and marketing will be dealt with elsewhere. Issues relating to system requirements and scalability are also dealt with in more detail in other chapters. In this chapter we will relate planning and decision making to the specific areas of software, hardware and content.
|
|
|
Background
|
|
|
Different gateways will have different strategic objectives which will be expressed in the key characteristics of the services they provide and the level of innovation to which they aspire. Some gateways may wish to deliver services using the latest technology and to gain a reputation for introducing new features and incorporating the most recent software developments; other gateways may be more concerned with inter-working with legacy technology and content and may regard leading-edge technology as inappropriate. Some gateways will want to spend resources on research and development work, while others may want to identify reliable existing products. Whatever the objectives of the gateway, some general principles can be identified which should inform decision making. |
|
|
Key factors for decision making
|
|
|
The gateway's decisions regarding hardware, software or content must take into account various imperatives. Each gateway must identify its own specific criteria and these criteria will differ depending on the gateway's priorities. However, there are some generic principles underlying the process of decision making which may be considered to be common to all gateways: 1. Planning for change. Search services are a growth area in the fluid Internet environment. This area is characterised by rapid shifts; new products are coming onto the market, new gateways are being set up and new technologies and standards are being developed. In addition the sectors in which gateways are working (education, libraries, knowledge industries) are also subject to change. Gateways need to be aware of new opportunities offered by change and be flexible enough to exploit them. In practical terms, this may mean delivering services to new audiences, incorporating new data structures, inter-working with services which may be based on different technologies. It may mean migrating to new systems, merging with other services, or taking on new service areas. 2. Decisions need to be based on criteria that are aligned with the gateway's strategic objectives. The gateway's strategic objectives need to be realised in day-to-day decisions. This means that all staff in the gateway need to be aware of the objectives and how they relate to their own decisions. For example, the choice of hardware needs to be informed by plans for growth, the choice of software must take account of the costs of inter-working with other services and the choice of metadata standards depends on users' search requirements and on the cost limitations for metadata creation.
3. Taking account of the environment. Decisions need to be informed by knowledge of the environment. Who are the ultimate users of the service and what are their requirements now? How will their needs change? What are the priorities of the investors (funding bodies) and how can they be influenced? Who are the competitors? What are the differentials that distinguish your gateway? The gateway will need to be aware of the effect of changes in the environment so that it can position itself to take advantage of opportunities, for example in the following ways:
|
|
|
Conclusion
|
|
|
Sound decisions regarding system and content will contribute to future proofing the gateway. However, lasting success depends on many factors outside the control of the gateway itself. Future proofing needs to be seen as just one part of the wider strategic planning process which gateways need to undertake. |
|
| Credits
|
|
|
Chapter author: Rachel Heery |
|
| Return to: Handbook Home DESIRE Home |
Search | Full Glossary | All References Last updated : 20 April 00 |
Contact Us © 1999-2000 DESIRE |
